
Life used to be so simple. When I joined Awin (or Affiliate Window as we were then called) our platform was a rather uncomplicated, monolithic, web application, sat on top of a pair of database servers. One database powered the platform and the other, an identical copy of the first, was only used in case something happened to the first.
Although this was nice and simple to understand, it presented many problems. The system was very difficult to scale (cope with an ever-increasing volume of traffic) and was not particularly resilient (good at coping with hardware failures or networking issues). Finally, everything was dependent on the central database, which meant that an issue in one area, say reporting, could also impact tracking.
The system has evolved a lot over the last 14 years, specifically to address these concerns, but given the recent issues, you may well be questioning whether we succeeded in making our platform resilient. The incident unquestionably impaired our services, but I would like to take a minute to explain how our platform is now built and how this allowed the disruption to be contained and ultimately allowed for a full recovery of the service with no loss of data.
I appreciate this may be a slightly bitter pill for those of you who were impacted by the reporting delays, particularly those who rely on the click-ref report. All I can really do to address that is to offer a sincere apology and to assure you that the lessons learned from this incident will be acted upon and will result in a further hardening of our system. We need to be your trusted partner and we will do our best to earn back any lost trust.
To give an idea of how our platform now operates, let me explain our core value stream (or how we turn tracking events into money).
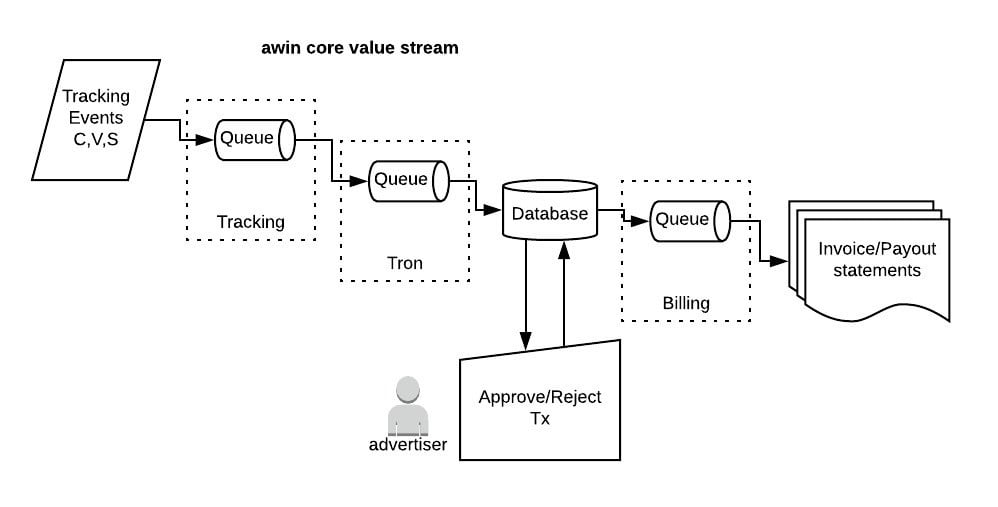
Unlike earlier times, the business events flowing through the Awin platform are not primarily stored in classic relational databases (MySQL). We now use messaging to store and process the events through message queues. Our primary messaging solution is called Kafka, and Kafka calls its message queues a topic. We operate several Kafka clusters for different purposes, with messages flowing from the upstream tracking cluster downstream to transaction processing, and further down to other processes like reporting, transaction notification, and ultimately to billing.
An important benefit of message queues is that they allow parts of a system to be decoupled from each other, which helps to limit failures from propagating through the system, particularly to parts of the system upstream from where the failure occurred.
What’s a cluster?
Put simply - a group of computers that run the same application and share the workload. Clusters help improve throughput (more processing power) but also increase resilience as the same data exists on more than one computer.
Our Kafka clusters store their configuration and shared state in a distributed configuration store called ZooKeeper.
We run our Kafka message queues and ZooKeeper on their own clusters of machines for both the above reasons.
So now you know a little about our systems, let’s take a look at what happened this month.
The road to disruption
- In January 2018, we took one tracking Kafka node out of service as it was reporting connection problems.
- On Feb 5th we experienced a Kafka phenomenon known as ‘Under-replicated partitions’ as a result of the January changes and while undertaking maintenance work to rebalance partitions in the cluster we ‘triggered’ a wave of inconsistencies within the tracking cluster.
- This meant that downstream systems (the systems reading from the Kafka queues) did not know what message they were supposed to read next and so would start again at the beginning of the queue.
- As we keep all messages for between seven and 30 days, depending on the topic, these were seen as duplicate events.
- Not all of our systems are resilient enough to properly cope with duplicates yet.
- Attempts to fix issues required us to replay old events, which caused further duplicates.
Technically, when could ‘under-replicated partitions’ occur?
This can happen when:
- The Kafka cluster is overloaded and followers are not able to catch up on leaders.
- We lost one or more Kafka instances, including networking timeouts between Kafka nodes
- We have or had inconsistencies on the ZooKeeper cluster, including networking timeouts to and from ZooKeeper nodes
No data was lost
Our actual tracking applications exposed to the external network have not been affected because there is no downstream dependencies on the rest of the infrastructure. They are independent nodes that contain all the logic and data they need to capture the raw tracking events. And we always had copies of all click, view, and sales events available for replay from within the Amazon cloud.
This allowed us to recover any downstream losses by playing back business events a second time - at the price of flooding the systems, which had to deal with normal traffic plus the playback events. As already mentioned, some of the systems also needed de-duplication afterwards. But we are confident we have not ‘lost’ business besides the damage to reputation and trust.
Actions taken
- Rebuilt the tracking cluster from scratch
- Reconfigured cluster topics favouring consistency over availability
- Disabled ‘unclean leader selection’ for the whole cluster
- Built an isolated ZooKeeper for the tracking Kafka cluster only
- Replayed data from 5th February onwards to assure nothing was lost
- De-duplication of records for Hadoop/HBase based reporting
- De-duplication of records for legacy reporting (PHP/MySQL based)
Next steps
- Ensure we are able to handle duplicates through the whole stack
- Have backup upstream and a replay solution at hand (i.e. always be able to replay from tracking).
- Setup an internal Kafka community of practice for knowledge sharing, best practices etc
- Review and improve out-of-office-hours support for the Kafka infrastructure
We also recognise that communication to users surrounding the issue could be improved. We got better at this as it progressed providing at least one daily update on our website and regular system notices on the user interface, but this should have happened from the outset and internal processes have been improved to address this.
We hope this more detailed explanation, although quite technical, reassures you of the resilience of our systems. If you have any questions or concerns, please use the support channels available to you or we will respond to comments or questions you add to this article.
Peter Loveday
CTO